春节期间,中国AI行业迎来一场前所未有的技术竞赛,各大厂商密集发布新一代大模型,推动国产AI技术进入全新发展阶段。这场竞争不仅体现在模型性能的突破上,更折射出中国AI企业争夺移动端入口的战略野心。
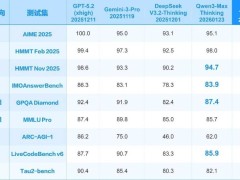
在这场技术狂欢中,智谱科技推出的GLM-5成为焦点。该模型参数规模从3550亿扩展至7440亿,激活参数提升至400亿,预训练数据量增加至28.5TB。更引人注目的是,GLM-5首次引入DeepSeek的稀疏注意力机制,在保持长文本处理能力的同时,将部署成本降低30%,Token利用效率提升25%。内部测试显示,其在编程开发场景中的性能较前代提升超20%,接近国际顶尖水平。
MiniMax的M2.5模型则选择差异化竞争路线。这款专为Agent场景设计的生产级模型,激活参数量仅100亿,却在编程与智能体性能上直接对标Claude Opus 4.6。其支持100 TPS的超高吞吐量,推理速度远超同类国际模型,在Excel高阶处理、深度调研等生产力场景中表现尤为突出。这种"小参数、高性能"的设计思路,为AI模型商业化提供了新范式。
头部企业的竞争愈发激烈。字节跳动一次性推出三款模型:视频生成模型Seedance 2.0、图像生成模型Seedream 5.0和通用大模型豆包2.0。其中Seedance 2.0凭借出色的视频生成效果,被业界视为潜在爆款产品。阿里巴巴则计划投入30亿元奖励计划,配合Qwen 3.5的发布抢占市场。DeepSeek更被曝正在研发支持100万Token上下文长度的V4版本,重点强化编码和超长提示词处理能力。
这场技术竞赛已产生显著市场效应。芯片板块率先受益,号称"国产GPU四小龙"的天数智芯股价单日涨幅达25%,壁仞科技涨近10%,兆易创新涨幅超8%。市场分析认为,AI算力需求的持续升温,将推动硬件厂商进入新一轮增长周期。上海某AI企业负责人指出,国产大模型从价格竞争转向技术竞争,标志着行业成熟度显著提升。
值得注意的是,本轮模型升级普遍聚焦实际应用场景。GLM-5在编程体验上逼近国际顶尖水平,M2.5专注生产力工具优化,字节跳动的新模型直指内容创作领域。这种转变反映出中国AI企业正在从技术追赶转向场景创新,试图通过差异化竞争打破国际垄断格局。随着春节发布季的持续,这场移动端入口争夺战将进入白热化阶段。